
Apside Quest : quand l'IA devient le maître du jeu de rôle
Apside Quest : quand l’IA devient le maître du jeu de rôle
Le jeu de rôle a toujours reposé sur l’imagination et l’interaction. Avec Apside Quest, l’équipe d’Apside Clermont-Ferrand franchit une étape audacieuse : remplacer le maître du jeu traditionnel par une intelligence artificielle. Ce projet illustre comment la technologie peut enrichir des expériences ludiques, tout en répondant aux attentes d’une audience moderne en quête d’immersion rapide et accessible.
Dans cet article, découvrez les coulisses de ce projet : de l’idée initiale à sa réalisation technique, en passant par sa démonstration lors du salon Volcamp.
Un concept ambitieux
L’objectif principal d’Apside Quest est de proposer de courtes parties, parfaitement adaptées pour des démonstrations techniques lors de conventions ou de salons. Chaque partie débute avec un contexte scénaristique élaboré par l’IA, suivi par des actions choisies par les joueurs. L’issue de ces actions est déterminée par des dés connectés, où chaque lancer influence directement le scénario.
Pour plonger les joueurs dans l’histoire, un narrateur, animé par une technologie de Text-to-Speech, donne vie au récit. De leur côté, les joueurs n’ont qu’à parler pour dicter leurs actions à l’IA, grâce à un système de Speech-to-Text.
Pour renforcer l’immersion, chaque étape de l’histoire est illustrée en temps réel par une image générée par une autre intelligence artificielle. La partie se déroule en cinq tours, culminant avec un combat final contre un boss. En cas de victoire, une animation spécialement conçue célèbre le succès des joueurs. Dans le cas contraire, ils sont envoyés au cimetière. Cette conclusion garantit une expérience immersive et mémorable, quelle que soit l’issue de la partie. À la fin, les joueurs sont invités à attribuer une note sur 5 et à fournir leur adresse mail. Ils reçoivent alors leur histoire complète en pièce jointe, pour revivre leur aventure ou la partager avec leurs proches.

Des défis technologiques : un projet à l’architecture ambitieuse
Pour donner vie à Apside Quest, une architecture robuste a été conçue :
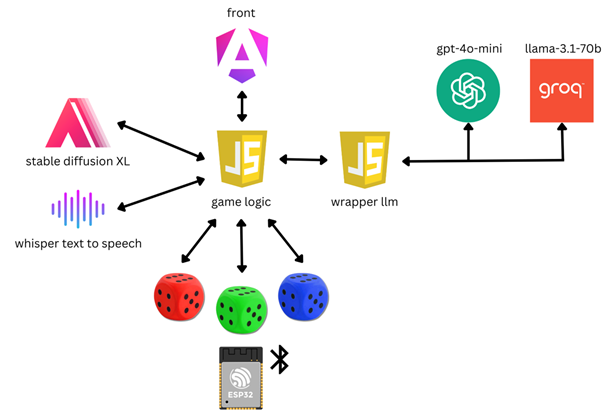
L’application repose sur une structure classique avec un frontend et un backend. Cependant, plusieurs aspects techniques méritent d’être soulignés :
- Un deuxième backend en Node.js est intégré pour encapsuler les différentes API de modèles de langage (LLM) disponibles sur le marché. Ce wrapper joue un rôle clé en offrant une interface unifiée pour interagir avec ces API, tout en gérant le contexte des prompts. Cela permet d’ajouter systématiquement le contexte nécessaire à chaque appel pour assurer une cohérence des réponses après plusieurs interactions.
- Une API Stable Diffusion XL hébergée localement sur notre machine a été mise en place pour garantir des temps de réponse rapides. Cette solution est essentielle pour maintenir une fluidité de gameplay et produire des illustrations en temps réel.
- Les dés connectés, véritable défi technique, nécessitent de surmonter des problématiques complexes liées au matériel et à leur fiabilité, afin d’assurer une expérience de jeu sans accroc.
Génération de l’histoire
Outils à notre disposition : Prompt-Engineering vs Fine-Tuning
Le Prompt Engineering consiste à concevoir des instructions optimales pour guider un modèle de langage (LLM) dans ses réponses. En ajustant soigneusement la formulation et le contexte des requêtes, il est possible d’obtenir des résultats précis sans modifier le modèle lui-même.
Le Fine-Tuning, en revanche, implique de réentraîner un modèle existant sur un ensemble de données spécifiques. Cette méthode permet de spécialiser le LLM pour des tâches bien définies ou pour mieux répondre à des besoins précis.
Lors du développement, les équipes optent alors pour le prompt engineering plutôt que le fine-tuning des modèles d’IA, et ce, pour plusieurs raisons.
Tout d’abord, le prompt engineering est une méthode bien plus flexible et rapide à mettre en œuvre. Elle permet d’obtenir des résultats pertinents en travaillant directement sur la formulation des requêtes envoyées au modèle, sans nécessiter une phase coûteuse et complexe de réentraînement sur des données spécifiques. Cette approche s’avère particulièrement adaptée à ce projet, où les scénarios et interactions évoluent constamment en fonction des actions des joueurs.
Contrairement au fine-tuning, cette méthode préserve l’intégrité et la polyvalence du modèle d’origine, garantissant ainsi une cohérence et une qualité de réponse optimales dans un large éventail de situations.
Enfin, elle offre une meilleure évolutivité, les prompts peuvent être ajustés à de nouveaux besoins sans nécessiter de réentraînement du modèle. Cela en fait un compromis idéal, alliant performance, agilité et rapidité d’itération.

Voici un extrait de prompt pour le tour numéro deux :
[…]
Vérifie attentivement que les actions demandées par les joueurs sont bien réalisables dans le contexte courant. Si ce n’est pas le cas, tu dois dire que l’action est impossible.
Tu dois bien vérifier que les actions respectent l’environnement présenté et les personnages externes. Les joueurs ne peuvent pas faire n’importe quoi.
Les joueurs vont tirer un dé, plus la valeur est haute, plus l’action est réussie. Si le dé tombe sur 1 l’action est un échec critique, elle doit échouer de façon spectaculaire. Si le dé tombe sur 6 l’action est un succès critique, elle doit réussir de façon incroyable.
Il faut que tu fasses évoluer les joueurs en fonction de leurs actions. L’environnement et les personnages externes vont aussi réagir en fonction des actions des joueurs. Les personnages peuvent gagner ou perdre des points de vie en fonction de leurs actions. Le maximum de points de vie est 10 et le minimum est 0.
Tu dois impérativement inventer une suite à l’histoire, avec un rebondissement inattendu, c’est très important.
[…]
La difficulté de cet exercice réside dans la recherche d’un équilibre délicat : une formulation trop détaillée peut submerger le modèle et entraîner des réponses incohérentes, tandis qu’un prompt trop succinct risque de manquer de précision, conduisant à des interprétations erronées.
Un défi à relever : garder une cohérence dans l’histoire
Lorsqu’un modèle de langage effectue une inférence, celle-ci est strictement unitaire : le modèle ne conserve aucune mémoire implicite des interactions passées entre deux appels. En d’autres termes, pour garantir une continuité et une cohérence dans les réponses, il est nécessaire de réinjecter dans chaque requête toutes les informations contextuelles et messages échangés jusqu’à ce moment. Bien que cette approche soit fonctionnelle, elle présente des implications sur la performance et la gestion des ressources. Plus le contexte devient long, plus le temps de traitement et les besoins en calcul augmentent, ce qui peut poser des limites pratiques, notamment pour des scénarios complexes ou prolongés. Cela souligne l’importance d’une gestion optimisée du contexte.
Pour résoudre cette problématique, les experts choisissent de ne pas réinjecter tous les messages à chaque appel, comme on pourrait le faire de manière simpliste. Ils injectent systématiquement le premier prompt système, qui définit le contexte initial de la tâche. Afin de garder un historique de l’histoire, ils n’injectent que les parties scénario du texte généré par le LLM. Cette méthode permet de limiter le contexte à injecter à chaque appel, tout en permettant au modèle de conserver les détails essentiels des tours précédents. Ce système fonctionne particulièrement bien pour l’épilogue, où, dans la grande majorité des histoires, des détails précis du début sont rappelés, ce qui donne un aspect particulièrement convaincant aux récits générés.
Si l’on considère le contexte à injecter pour le prompt du tour 4, voici la comparaison entre l’approche simpliste et l’approche optimisée dans le cadre de notre application. Soit N la taille du prompt système et M la taille d’une réponse du LLM. En prenant en compte les prompts utilisés pour générer l’histoire, nous pouvons observer que N > M.
Ainsi, dans cette approche optimisée, le contexte à injecter est de N + 3M, soit bien plus petit que dans l’approche naïve, où il serait de 3N + 3M. Cela permet de réduire considérablement la taille du contexte à injecter, optimisant ainsi les performances et la gestion des ressources.
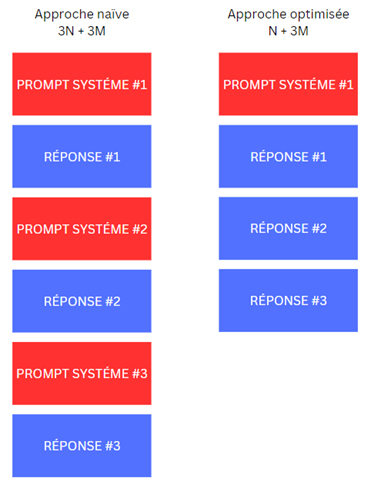
N’y a-t-il pas une perte d’information si les prompts systèmes intermédiaires ne sont pas injectés ? Dans notre cas d’utilisation spécifique, ils ont déterminé que seul le contexte initial et l’évolution de l’histoire sont nécessaires. Il n’est pas indispensable d’inclure toutes les étapes intermédiaires de la construction pour obtenir un résultat satisfaisant. Cette approche nous permet de conserver l’essentiel tout en optimisant la taille du contexte à injecter, sans compromettre la qualité des réponses générées.
Une dernière problématique : diversifier les mise en contexte
Lors de nos tests, les experts ont constaté que l’utilisation d’un prompt identique à chaque exécution produisait des résultats très similaires. Cela s’explique par la manière dont les modèles de langage traitent les requêtes : chaque mot ou concept est représenté sous forme de vecteur dans l’espace latent du modèle, un espace multidimensionnel où les relations sémantiques entre concepts sont encodées. Lorsque le même prompt est utilisé, le modèle suit des trajectoires similaires dans cet espace, ce qui limite la diversité des réponses générées.
Pour contourner ce phénomène, une composante aléatoire est introduit en variant certains mots-clés liés au thème, tels que “comique”, “amusant”, “drôle” ou “humoristique”. Cette variation modifie légèrement la position du prompt dans l’espace latent, forçant le modèle à explorer des régions adjacentes et produisant ainsi des réponses plus variées. Ce comportement met en lumière la sensibilité des LLM aux variations subtiles dans les formulations, soulignant l’importance d’une ingénierie de prompts dynamique pour éviter la stagnation des résultats.
Une fois l’histoire générée, cohérente et divertissante, il est temps de l’illustrer comme il se doit.
Génération d’image
Le choix du modèle
Stable Diffusion est un modèle d’intelligence artificielle spécialisé dans la génération d’images à partir de descriptions textuelles. Il utilise un processus de diffusion inverse, transformant un bruit aléatoire en une image cohérente en se basant sur les mots-clés fournis. Pour obtenir des résultats précis, il est crucial de formuler un prompt clair et concis.
Cependant, de nombreux modèles dérivés de Stable Diffusion ont été fine-tunés pour des usages spécifiques. Dans le cadre de ce projet de jeu de rôle, ils ont recherché un modèle avec une esthétique médiévale, afin de rendre les visuels plus convaincants. Le modèle choisi est DreamShaper8, un dérivé de Stable Diffusion 1.5, qui se distingue par une inférence rapide et des résultats correspondant parfaitement à l’esthétique recherchée. Voici quelques exemples de génération réalisés avec ce modèle.

Toute une histoire pour convertir une histoire en image
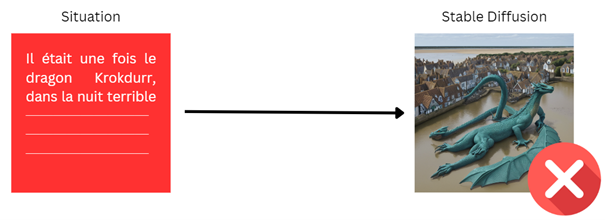
Générer des images correspondant à une histoire en français pose plusieurs défis, notamment celui de transmettre fidèlement une situation complexe sous forme visuelle. Si le texte de l’histoire est utilisé directement comme entrée pour Stable Diffusion, le résultat est souvent insatisfaisant. L’excès d’informations dans le texte, combiné à des descriptions narratives moins structurées, peut entraîner la création d’images surchargées ou incohérentes, qui ne reflètent pas fidèlement la scène souhaitée.
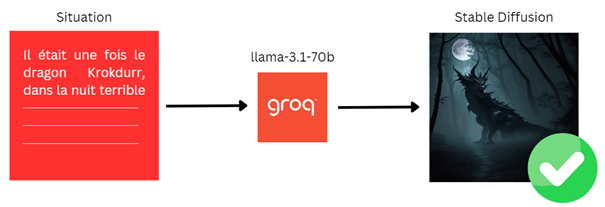
Pour contourner ce problème, ils utilisent un LLM spécialisé qui transforme la situation narrative en un prompt simplifié et optimisé pour Stable Diffusion. Ce prompt prend la forme d’une liste concise de mots-clés descriptifs, en anglais, incluant le lieu, l’ambiance, les personnages et leurs actions. Cette étape d’interprétation permet de condenser les éléments essentiels de l’histoire dans un format que Stable Diffusion peut exploiter efficacement, garantissant ainsi des images visuellement claires et cohérentes avec le contexte narratif.
Cette étape est gérée par un prompt spécifique qui est le suivant.
[…]
You need to generate a prompt for generating an image with the following format : [location] [ambaince] [light] [characters] [action]
You must not use nicknames or specific name in the prompt.
Example : Dark forest, mysterious atmosphere, full moon, a knight, fighting a dragon.
Your situation is the following : {situation}
The prompt must be 15 words long maximum, it’s very important you respect this limit.
[…]
À partir de n’importe quelle situation, la sortie suit toujours un format prédéfini, composé des éléments principaux : location, ambiance, light, characters, et action. Le choix du modèle Llama 3.1 70b a été motivé par sa rapidité de réponse sur ce type de prompt relativement court. Les équipes souhaitent minimiser le temps d’attente entre l’apparition de l’histoire aux joueurs et la génération de l’illustration. Pour gagner encore plus de temps, les Apsidiens optent pour l’API de Groq, qui offre des temps de réponse inégalés sur le marché.
Maintenant que les joueurs disposent d’un récit amusant et illustré, il est temps d’ajouter un peu d’aléatoire dans leur quête.
Un destin incertain, commandé par un lancer de dé
Afin d’introduire une part d’incertitude dans l’aventure des futurs joueurs, l’idée de pondérer leurs actions avec un dé est rapidement apparue. De plus, pour attirer l’attention et rendre l’expérience plus immersive, les Apsidiens choisissent d’utiliser des dés géants en mousse, d’environ quinze centimètres de diamètre.
Cette partie du développement a été la plus longue, car ils ont dû faire face aux défis du prototypage, des tests en conditions réelles et des contraintes budgétaires.
La partie électronique, intégrée à l’intérieur du dé en mousse, comprend un microcontrôleur ESP32 qui assure la communication via Bluetooth Low Energy (BLE). Lorsqu’un dé est lancé, le gyroscope détecte l’attraction terrestre et permet de déterminer sur quelle face se trouve le dé. Les informations sont ensuite envoyées via le bus série Bluetooth avec un débit de 5 messages par seconde. Le backend reçoit ces données et les transmet à l’application frontend via un WebSocket.
Une version Wi-Fi de cette communication avait été mise en place initialement, mais les problèmes de consommation énergétique et de goulot d’étranglement avec plusieurs dés nous ont conduit à abandonner cette implémentation.
Il est maintenant temps de tester Apside Quest en conditions réelles.

Conclusion, échec ou réussite critique ?
Apside Quest est le projet phare de notre équipe de Clermont-Ferrand sur leur stand lors de la conférence technique Volcamp à Clermont-Ferrand en 2024. Le succès fut au rendez-vous, avec près de 85 joueurs sur les deux jours de la conférence. La note moyenne des participants à la fin de chaque partie fut de 4,8 sur 5. De plus, les joueurs sont repartis avec de véritables dés de jeu de rôle dans un sachet floqué Apside !
Une belle façon de lier expertises techniques avec les sujets actuels de l’IA générative, et les possibilités offertes par l’univers du jeu de rôle.










